Strona internetowa to wizytówka każdego biznesu internetowego. Wypełnianie i aktualizowanie treści stron z dużymi katalogami produktów jest czasochłonne. Dlatego pozbawieni skrupułów konkurenci często kradną treści z innych stron internetowych.
Co to jest parsowanie?
Parsowanie to zbieranie informacji z witryn internetowych i zasobów stron trzecich. Zajmują się tym albo specjalnie zatrudnione osoby, albo programy (parsery).
Parsery kradną zawartość kodu, treść strony oraz informacje znajdujące się w domenie publicznej.
Jaki jest cel parsowania?
Parser analizuje dane witryny na podstawie określonych filtrów, zbiera treści, porządkuje i przekształca teksty i inne elementy. Najczęściej analizowane są witryny zajmujące się sprzedażą towarów i usług.
Parsery potrafią:
- Kraść katalogi produktów. Każdy produkt w sklepie internetowym posiada własny opis i żeby nie wypełniać ręcznie kart produktów, te informacje są parsowane z innych źródeł.
-
Konkurenci śledzą zmiany cen towarów na rynku w celu dostosowania cen swoich zasobów.
- Zapożyczać nowe pomysły i wyjątkowe oferty od konkurencji. Podczas analizowania konkurenci często przywłaszczają sobie Twoje warunki, pomysły i nowe oferty podczas sprzedaży podobnych produktów.
- Kraść bazy danych klientów zawierające osobiste (poufne) informacje. Za pomocą parsowania możesz stworzyć bazę klientów. W tym celu analizowane są dane kontaktowe użytkowników: sieci społecznościowe, e-maile, telefony. Dane muszą znajdować się w otwartym zasobie, archiwum lub CV.
- Obniżać pozycję konkurentów w wynikach wyszukiwania. Witryna konkurenta, który skopiował od Ciebie informacje, zostanie zindeksowana przez wyszukiwarki. Przez to w wynikach wyszukiwania Twoja witryna może znajdować się niżej niż witryna konkurencji.
Parsing jest legalny??
Informacje chronione prawem autorskim nie mogą być wykorzystywane do celów osobistych. Jednak zbieranie i wykorzystywanie informacji znajdujących się w domenie publicznej nie jest uważane za naruszenie prawa. Dlatego zgodnie z prawem nie będziesz mógł wystąpić do konkurencji z roszczeniem o pobranie danych z Twoich otwartych zasobów.
Jak chronić się przed parsowaniem?
Oto sposoby ochrony przed parsowaniem:
Metoda 1. ДAby chronić witrynę, możesz spróbować znaleźć adres IP, z którego próbują parsować Twoją witrynę i zablokować go. Jednak ta metoda jest czasochłonna i rzadko używana. Istnieje również ryzyko zablokowania „dobrego bota”, który jest indeksatorem wyszukiwarek. Ta metoda nie ochroni Twojej witryny przed nowymi parserami i za każdym razem będziesz musiał ręcznie blokować podejrzane adresy IP.
Metoda 2. Wdrożyć JavaScript na strony swojej witryny. Kod JS może spowolnić parserów, ponieważ wiele z nich nie są nauczeni go ignorować. Ponadto skrypt może zatrzymać pracę przydatnych robotów.
Metoda 3. Najskuteczniejszą opcją jest zainstalowanie specjalnego skryptu, na przykład Antibot Pro. Chroniąc witrynę, Antibot Pro przenosi podejrzane adresy IP na stronę weryfikacyjną i umożliwia dostęp do witryny prawdziwym użytkownikom. Antibot zapamiętuje adresy IP prawdziwych użytkowników i nie przeszkadza im, gdy ponownie odwiedzają witrynę.
Antibot Pro sprawdza Twój adres IP:
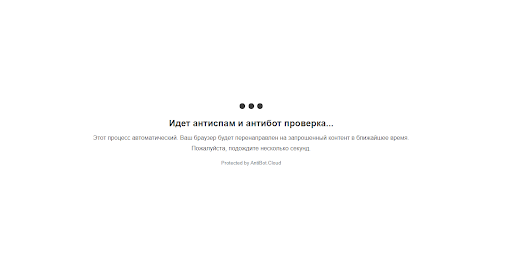
Tak wygląda sprawdzenie podejrzanego adresu IP:
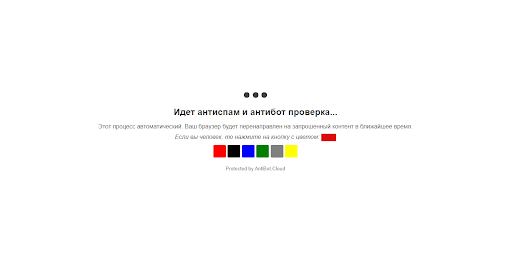
Gdy parser-robot odwiedza Twoją witrynę, Antibot Pro blokuje mu dostęp do niej:
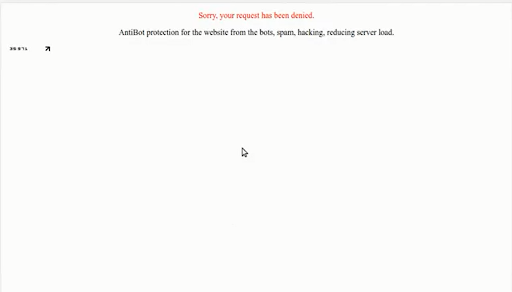
Wynik
Parsowanie jest niebezpieczne dla wszystkich witryn. On może służyć do kradzieży katalogów produktów, zbierania informacji o cenach sklepów, kradzieży unikalnych ofert i baz danych użytkowników. Jeśli nie zabezpieczysz strony przed robotami parserowymi, możesz stracić pozycję w wynikach wyszukiwania.
Uniknąć tego typu ataku możesz, chroniąc witrynę za pomocą specjalnych programów, takich jak Antibot Pro.